Hello ![]()
Is it possible to generate frequencies from an image sequence, for example the luminance or the colour? I’m interesting in creating a generative audio piece.
Thanks!
Hello ![]()
Is it possible to generate frequencies from an image sequence, for example the luminance or the colour? I’m interesting in creating a generative audio piece.
Thanks!
This seems pretty doable. There’s a node called Make Audio Wave which lets you create a sound wave with a particular freq.
I’ve made a little patch (see below) which samples average lightness of camera image, and changes the frequency of the audio tone. It’s not very interesting at the moment but you can it from here!
lightSound.vuo (4.31 KB)
Hi,
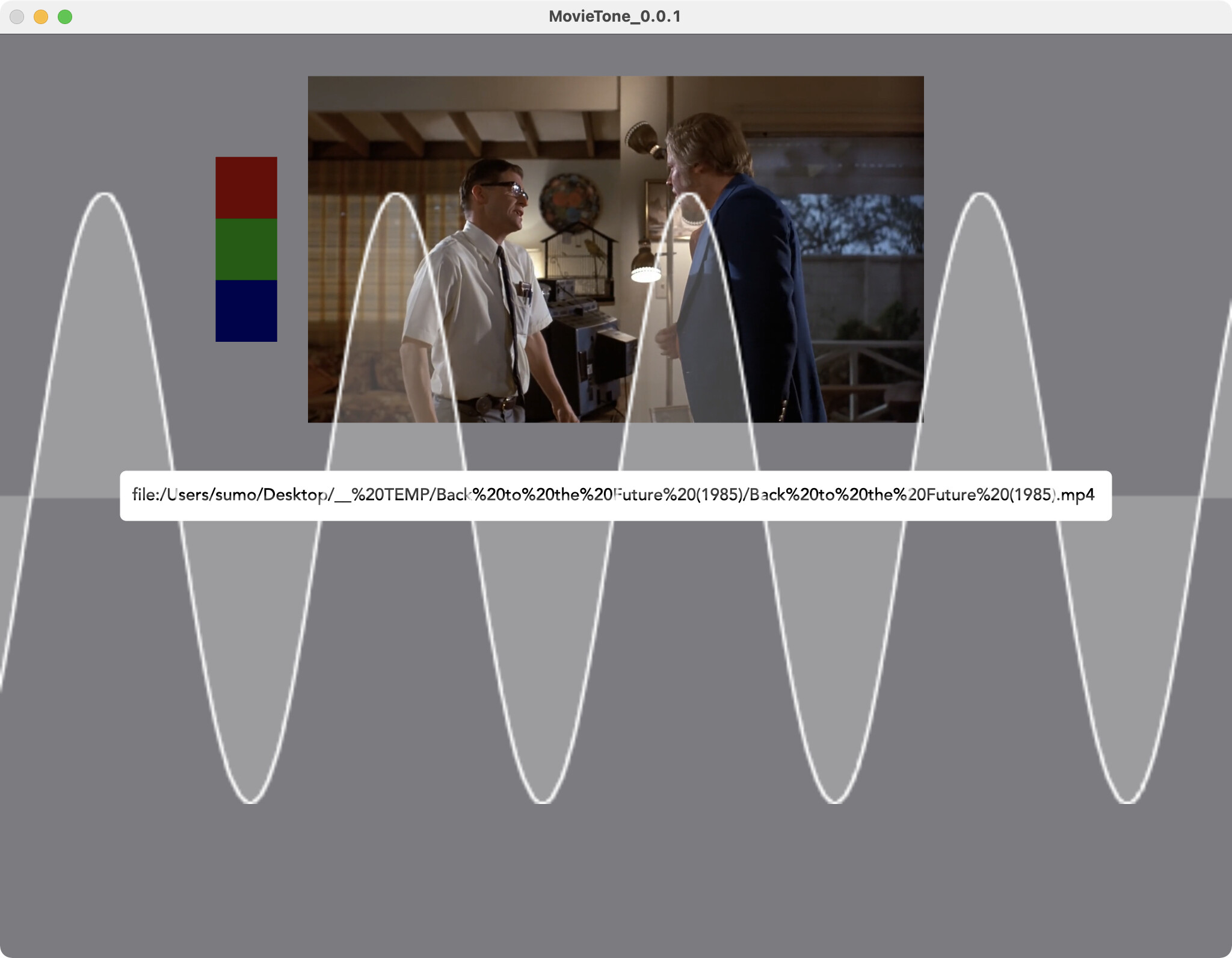
I’m working on the same idea analysing movies to extract frequencies based on the movie frame colour pallet. I have the basics working sending OSC messages out and saving the analysis to a jason file for later processing. But I was just looking up how to create an audible tone and I found this thread :-) Looks like you have to create a MIDI note and then you could possibly play it using Vuo? Not quite sure what my use case is yet, possibly an installation or linked to a performance.
Still quite a way to go with this but here’s a screen grab of the UI element:
I’m using the ‘Receive File Drags’ UI node to enter the movie URL which could be used to create a dynamic control surface for performance or audience interaction. The reference movie, Back to the Future (1985)… what else :-)
@keithlang gosh I was overthinking the audio output function. I checked your composition and realised all I needed was the ‘Send Live Audio’ node! Thats a visual person trying to do audio :-)
![]() Yes, it is a little counterintuitive (maybe Vuo should throw a warning if a node isn’t actually producing anything) but I think the Vuo team have enough on their plate for now.
Yes, it is a little counterintuitive (maybe Vuo should throw a warning if a node isn’t actually producing anything) but I think the Vuo team have enough on their plate for now.
Ping this thread if you get stuck!
@Joëlle Do you want it to sound “nice” or are you more into the noise/random frequencies with this one?
At a base level, you can extract the color values with the Sample Colors from Image node and feed it to a Get RGB/HSL Values. Then you should have numbers in the range of 0-1 to further manipulate.
For the “nice” approach, and following @2bitpunk’s suggestion take the floor of each of the values * 127 to get a MIDI note. For the luma value, I’d use a Calculate node with a formula of floor((127*(R+G+B))/3) - or just the L value from the HSL node.
Taking it a step further, you can also make a list of numbers and scale the color values to select an item from the list. Then you can use scales and make chords with notes from each component and volume/velocity from the luma to get different expressions (https://feelyoursound.com/scale-chords/c-phrygian/ // https://newt.phys.unsw.edu.au/jw/notes.html). I wouldn’t bother with using more than two/three octaves in such a scenario though.
For the probably-not-so-nice-but-noisy approach, taking the RGB values into a Scale node with a source from 0-1 and scale out from 120-12000 fed into a Make Sound Wave (or something similar, can’t remember the name now) will probably yield interesting results.
This noisy example (in the experimental music domain) is based on a simple frequency-from-image method with the visual created in VDMX, syphoned to Vuo to generate the frequency, then the waveform layer is syphoned back to VDMX, the frequency-from-image audio is used to animate the objects in VDMX (using the LoopBack app for audio routing)… and around it goes. Not sure it’s a nice noise but I can see where I’m going now :-)
@MartinusMagneson for the visual people this is where it gets hard, I have little if any music theory but have worked with beats as a VJ for 30+ years (not quite retired yet). Cut me in half and you will find a 120bpm tattoo in there somewhere :-) I guess the natural framework for this would be something like SuperCollider but I like the idea and challenge of using Vuo’s limited audio synthesis. Joëlle and my projects will have the same starting point but will undoubtedly end up being unique.
@Joëlle One thing I might suggest is narrowing the sample area or at least making this flexible. It could help find a sweet spot for analysis instead of averaging out the full frame. I’ve used this method for analysing live video feeds and by having a small sample area you can cut out a lot of noise and create a smoother data stream. This could be a mouse click to select the sample area and sliders to adjust the height and width.
It does help to have some music/production theory & practice under the belt ![]() ! I have used NIs Reaktor for quite a few years for custom stuff, so I’ve never gotten into Supercollider (although I’ve heard it mentioned a few times). I find the Reaktor “core” approach to be pretty cool. You get a sample rate clock, a few basic math operators, some basic memory modules, and off you go. All of the more high level stuff is made with the most basic blocks/nodes in nested macros. This way you can really dig down in the rabbit hole in the same framework if you wonder how something works and/or you want to modify or build on it. I haven’t looked at the audio generating capabilities of Vuo, but I assume all standard additive/subtractive synthesis options should be viable.
! I have used NIs Reaktor for quite a few years for custom stuff, so I’ve never gotten into Supercollider (although I’ve heard it mentioned a few times). I find the Reaktor “core” approach to be pretty cool. You get a sample rate clock, a few basic math operators, some basic memory modules, and off you go. All of the more high level stuff is made with the most basic blocks/nodes in nested macros. This way you can really dig down in the rabbit hole in the same framework if you wonder how something works and/or you want to modify or build on it. I haven’t looked at the audio generating capabilities of Vuo, but I assume all standard additive/subtractive synthesis options should be viable.
I haven’t looked at the audio generating capabilities of Vuo, but I assume all standard additive/subtractive synthesis options should be viable.
Only with the most basic stuff, and good luck with that.
I’m a Bidule user from way back, nodes and noodles all the way. Same audio concepts as Reaktor core, except NI/Reaktor’s user base and library is vast. I love the noodles.
Anyway, my two cents, in response to the OP:
Step 1: decide on some visual parameters – for example, luminance/brightness, hue, saturation, R,G,B, alpha, etc. Less headaches if you commit to normalized ranges – 0 to 1 for all parameters.
Step 2: make some artistic decisions – for example, what sound parameter does red control? Filter and shape the visual data – produce good, usable data.
Step 3: set up something in the audio world to receive data from your visual parameters, probably translated to either MIDI or OSC. Both are versatile and powerful.
Go to step 2, repeat.
Let’s say luminance to frequency:
Then there are many ways to “quantize” the data to play more meaningful/“musical” notes/combinations.
Besides frequency (or pitch or note number), there are a whole bunch of other audio parameters. For example, there’s amplitude (velocity, volume), many shades of timbre (EQ stuff/filters, modulation, waveshaping/distortion), fading between sounds/audio files/samples, selecting some synthesizer preset, things like speed/rate (frequency, but for some other sound shaping thing), or other settings like “thickness”, “sparseness”, and so on and so forth.
To use an audio/modular synthesis term, I might try to think of luminance as a “modulator” for some parameter – or more likely some set of audio parameters.
Did a little exploration using Vuo’s audio stuff. More interesting than expected!